Web Scraping 101
Are you a business professional? Find the information you need to effectively incorporate web scraping into your business.
Are you a developer? Learn about the latest techniques to extract data from all kinds of websites.
Are you simply looking to learn more about web scraping? This website has all the information you need to understand the basics of web scraping and provides links to resources to help you learn everything else you need to know.
1) What is web scraping?
Web scraping is the extraction of data from websites and may also be referred to as "data scraping" or "web harvesting." Generally, this refers to an automated process but would also include the manual copying and pasting of data from any online source, such as an HTML web page or PDF, CSV, JSON, or XML document.
Web scraping can take several forms. Most commonly, programmers write custom software programs to crawl specific websites in a pre-determined fashion and extract data for several specified fields. These programs can interchangeably be called "bots," "scripts," "spiders," or "crawlers." Companies also maintain software that allows users to build web scraping projects without writing any lines of code by using a point-and-click graphical user interface.
Once data is extracted from a website, it is generally stored in a structured format, such as an Excel file or CSV spreadsheet, or loaded into a database. This "web scraped data" can then be cleaned, parsed, aggregated, and transformed into a format suitable for its end-user, whether a person or application.
Tip: See the glossary for an explanation of key web scraping terms.
Exhibit 1: Visual interpretation of web scraping
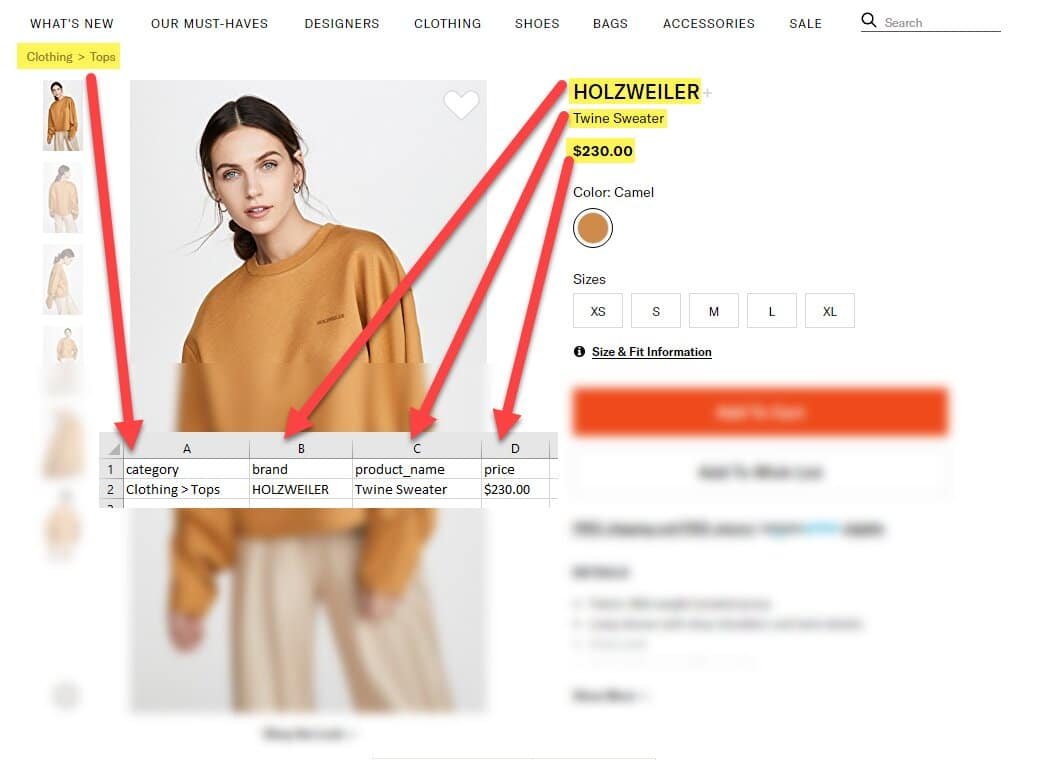
Why is web scraping used?
Web scraping is used for a wide variety of reasons. Generally, it's implemented as a much more efficient alternative to manually collecting data since it allows much more data to be collected at a lower cost and in a shorter amount of time. For more detail on specific use cases, see Section 2.
Web scraping vs. Web crawling
Web scraping and web crawling refer to similar but distinct activities. Web scraping focuses on the extraction of data from web pages while web crawling simply refers to the automated process of visiting many pages of one or multiple websites according to a set of rules. This is done commonly to index a site's contents. Thus, a web scraping project may or may not involve web crawling and vice versa.
How does automated web scraping work?
To automatically extract data from websites, a computer program must be written with the project's specifications. This computer program can be written from scratch in a programming language or can be a set of instructions input into a specialized web scraping software.
The computer program then sends requests to websites for certain pages. At this point, various types of authentication may take place and the website may or may not respond with the requested content. Assuming the content is returned, the program then parses the response to extract the data into a structured format for further processing.
The actual extraction of data from websites is usually just the first step in a web scraping project. Further steps usually must be taken to clean, transform, and aggregate the data before it can be delivered to the end-user or application. For example, person names might be split into first and last names, state abbreviations could be mapped to their full name, and product prices could be converted into numeric data types by removing dollar signs and commas. Finally, the data might be summarized at a higher level of detail, to show average prices across a category, for example.
Many types of software and programming languages can be used to execute these post-scraping tasks. Common options include Excel, Python, and R. Excel offers the lowest learning curve but is limited in its capabilities and scalability. R and Python are open-source programming languages that require programming skills but are nearly limitless in their ability to manipulate data. Large scale applications may require more advanced techniques leveraging languages such as Scala and more advanced hardware architectures.
What are the advantages of automated web scraping?
Automated web scraping provides numerous advantages over manual collection. First and foremost, an automated process can collect data much more efficiently. Much more data can be collected in a much shorter time compared to manual processes. This also makes frequent runs much more economical. Second, it also eliminates the possibility of human error and can perform complex data validation to further ensure accuracy. Finally, in some cases, automated web scraping can capture data from web pages that is invisible to normal users.
What are the key challenges?
The first challenge in web scraping is knowing what is possible and identifying what data to collect. This is where an experienced web scraper has a significant advantage over a novice one. Still, once the data has been identified, many challenges remain.
First, individual websites can be difficult to parse for a variety of reasons. Websites may load slowly or intermittently, and their data may be unstructured or found within PDF files or images. This creates complexity and ambiguity in defining the logic to parse the site. Second, websites can change without notice and in unexpected ways. Web scraping projects must be set up in a way to detect changes and then must be updated to accurately collect the same information. Finally, websites may employ technologies, such as captchas, specifically designed to make scraping difficult. Depending on the policies of the web scraper, technical workarounds may or may not be employed.
Web scraping vs. Web APIs
A web API (Application Programming Interface) allows programs to interact with other programs via HTTP
requests (in other words, loading a URL). Often, this allows a user to download data based on specified
parameters. For example, the following URL returns a (fake) list of employee names:
http://dummy.restapiexample.com/api/v1/employees. Though similar, this is generally considered to
be distinct from web scraping and is better categorized as an aspect of application development. Working with
web APIs does not come with many of the challenges unique to web scraping. Web APIs come with comprehensive
documentation, ensure consistency in the data that is returned, and are built to allow for efficient access to
the data.
2) Common use cases
The applications for web scraping are endless and can be found across all industries. Businesses, consumers, and researchers alike all have uses for web scraped data. Some of the most common applications include the following:
-
Product tracking: Consumers may be interested in tracking the prices, reviews, or inventory of certain products. Businesses may be interested in developing competitive intelligence based on price tracking of competitors’ products.
-
Marketing: Businesses across all industries may be interested in gathering contact information, such as email or physical addresses, of potential leads. Web scraping can also be used to learn more about potential B2B leads by analyzing data from target companies’ websites.
-
Market Research: Useful data exists across many websites all over the internet but is not consistently structured to allow for easy analysis. A web scraping project can be set up to consolidate this data into a well-structured dataset for further analysis to inform business decisions. Examples of available data include government reported statistics, social media activity, and transaction data.
-
Archiving: Web scraping can be used to create a historical record of point-in-time data or to create a complete, offline copy of a website. This can be useful for the owner of the site or for users of another site’s data.
What other data can be scraped?
The possibilities are endless. The following non-exhaustive list provides more examples of potential use cases:
Note: We do not endorse the unconditional scraping of sites listed below. These are provided only as examples.
-
Social Media
- Social media presents an abundance of data that can be used for a wide variety of purposes. For example, contact information can be scraped to assist in marketing, posts can be analyzed to uncover what is trending, engagement can be measured to assess consumer sentiment towards brands, or news can be tracked in real-time, faster than traditional media outlets.
- Relevant sites:
- Facebook.com
- Instagram.com
- LinkedIn.com
- Twitter.com
- TikTok.com
- YouTube.com
-
Real Estate
- Information on millions of properties can be found online. Investors and brokers can use listings data to make better-informed business decisions.
- Relevant sites:
- Loopnet.com
- Showcase.com
- Trulia.com
- Zillow.com
-
E-commerce
- Consumer spending comprises almost 70% of GDP in the US, and e-commerce represents a significant and the fastest-growing segment of it. Tracking products online can be useful across nearly every industry and for both consumers and businesses. Businesses can use e-commerce data to track competitor prices online, manufacturers can ensure MAP ("minimum advertised price") compliance at their retailers, and consumers can compare prices over time and across retailers. Other data points that can be tracked include reviews, availability, inventory, and product attributes, among others.
- Relevant sites:
- Amazon.com
- BestBuy.com
- eBay.com
- Expedia.com
- Hotels.com
- Flights.Google.com
- Footlocker.com
- HomeDepot.com
- Hotels.Google.com
- Kayak.com
- Lowes.com
- Target.com
- Walmart.com
-
Search Engines
- Search engines can be scraped to track data on the positioning of results for certain keywords over time. Marketers can use this data to uncover opportunities and track their performance. Researchers can use this data to track the popularity of individual results, such as brands or products, over time.
- Relevant sites:
- Bing.com
- Google.com
- DuckDuckGo.com
-
Market/Economic Research
- Much data exists online to perform market research, but it can be difficult to seamlessly analyze data across various sites. Web scraping can be employed to merge these datasets into a common format.
- Relevant sites:
- Data.gov
- Fred.StLouisFed.org
- Glassdoor.com
-
Sports Stats
- Sports stats have grown in sophistication and importance across all major professional sports, and fans have shown increased interest in this type of data. Bettors and fantasy sports players can also use this data to make better-informed decisions.
- Relevant sites:
- MLB.com
- NBA.com
- NFL.com
- NHL.com
- PGATour.com
-
Marketing
- Marketers can pull contact information from pubic websites to generate lists of targeted leads for
their products and services. Names, demographic information, email addresses, and phone numbers can all
be pulled through various sites, such as Facebook, LinkedIn, and Zillow. A multitude of miscellaneous
sites can also be scraped. For example, lawyers in California can be found by searching through this
portal:
http://members.calbar.ca.gov/.
- Marketers can pull contact information from pubic websites to generate lists of targeted leads for
their products and services. Names, demographic information, email addresses, and phone numbers can all
be pulled through various sites, such as Facebook, LinkedIn, and Zillow. A multitude of miscellaneous
sites can also be scraped. For example, lawyers in California can be found by searching through this
portal:
-
Legal
- Lawyers can use information scraped from legal filings and case dockets. Most states, counties, and municipalities provide online access to court records.
-
Investment Research
- Investment research analysts can track a wide variety of information online to help them monitor the financial performance of companies. For example, analysts can track promotional activity to discover struggling brands, reviews of new products to see which are gaining traction, and store locations to assess exposure to demographic trends. Traditional data such as financial statements and stock trading activity can also be scraped.
-
Journalism
- Journalists can scrape data from websites to help provide concrete evidence for their reports.
-
Other
- Entire websites can be copied as backups or for offline use.
- Individual web pages can be tracked and monitored for changes.
- Images can be downloaded for further analysis, such as machine learning.
- Job listings can be scraped an aggregated from sites such as Indeed.com.
Example case studies
-
UBS Evidence Lab (link)
- Industry: Investment research
- Type of data collected: e-commerce pricing
- Description: UBS Evidence Lab is a group within the investment research division of UBS, a global investment bank. Its goal is to generate proprietary research to aid in the analysis of public companies' financial performance. UBS Evidence Lab operates an extensive web scraping program to track all kinds of unique web-based data that, though public, is not generally available to most investors. For example, this research report demonstrates their work to track prices of infant formula in China. They scraped over half a million price observations over the course of several years.
-
camelcamelcamel (link)
- Industry: E-commerce
- Type of data collected: e-commerce pricing
- Description: camelcamelcamel operates a website that allows consumers to view the price history of products sold on amazon.com to help them know whether they are getting a good deal. Web scraping can be employed to generate a pricing database, such as this, for many different kinds of consumer products and services, such as air travel or car rentals.
-
hiQ Labs (link)
- Industry: B2B Data
- Type of data collected: Employee data on Linkedin.com
- Description: hiQ Labs scrapes public information on Linkedin and analyzes the data to help companies' human resources efforts. This data helps to identify employees at risk of leaving so that preemptive action can be taken and helps recruiters find individuals with skill sets similar to top employees of their firm.
-
CareerBuilder (link)
- Industry: Employment website
- Type of data collected: Job listings
- Description: CareerBuilder operates a website that allows job seekers to search for jobs. The company leverages web scraping to collect job listings from many sites.
3) Industry overview
History of web scraping
The history of web scraping is nearly as long as the history of the internet itself. In the earliest days of the internet, programs were built to crawl websites and index their contents. Their purpose was to allow people to easily find information online. The most prominent initial use case was to power search engines, such as Google. Web scraping as it's currently known started growing in popularity around 15 years ago and has grown steadily since then.
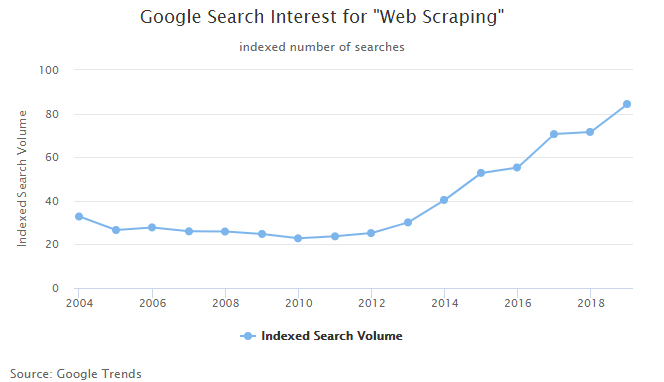
Lower costs have been the primary driver of the acceleration in growth since 2012. Key costs of web scraping include internet bandwidth, computing power and storage, and labor; and all, besides labor, have decreased drastically over that time. Furthermore, the amount of data available to scrape has increased exponentially and has contributed to greater demand for web scraped data. More details on each driver are below:
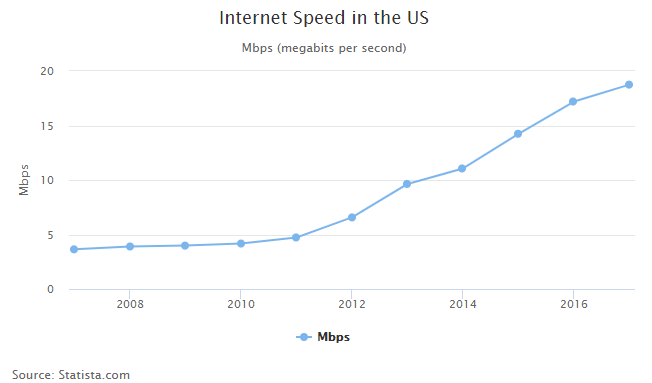
1) Cheaper internet bandwidth: Web scraping became more practical with the spread of high-speed internet. For many projects, dial-up connections would not provide the speed required to complete a run within a reasonable amount of time, and the cost of more bandwidth could outweigh the potential benefits. As the cost of high-speed internet fell and average speeds rose, projects that were not economically viable now became worthwhile to run.
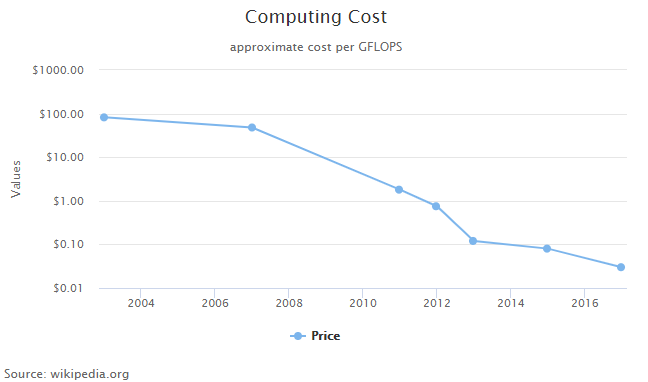
2) Cheaper computing and storage: Computing power and storage are required for web scraping projects and historically have been a significant component of overall costs. However, computing costs have continued to fall as they have since the development of the first microprocessor and have now reached a point where it is no longer a significant barrier to running web scraping projects. Similarly, storage costs have also fallen, which has made the handling of large data sets much more economical.
3) Rise of cloud services: The rise of cloud services, such as Amazon Web Services, Microsoft Azure, and Google Cloud Platform, have made web scraping at scale feasible without the need to make a large upfront infrastructure investment. Cloud services also provide the flexibility to only pay for computing resources when they are being used. Thus, large web scraping projects that require significant computing resources would only incur costs when they are being run. This contrasts with on-premise hardware which must be paid for whether it is being fully utilized or not.

4) Growth in the volume of information available to scrape: The number of websites has grown exponentially over the past 20 years. The general decline in computing costs that has made web scraping more economical has also made it much easier for organizations to produce data ("Big Data", exhaust data). The general growth in this production and analysis of data has provided a greater variety and volume of valuable data available to scrape.
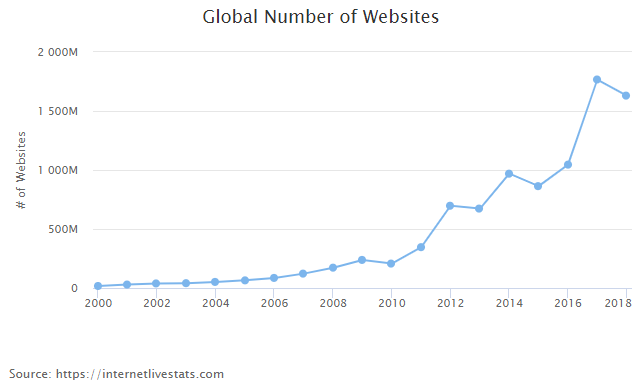
Who uses web scraping today?
Despite this acceleration in growth over the past 5 years, web scraping remains a nascent industry. While web crawling by search engines has been thoroughly institutionalized, web scraping remains seen as more of a "hacker" skill, occasionally practiced by individual developers in their free time. Still, the industry is slowly becoming more institutionalized evidenced by the growth in corporate web scraping departments and publication of web scraping standards by various organizations.
Web scraping has now become standard practice across industries such as e-commerce, investment research, and real estate, but it's still relatively early in its adoption. Even firms that have started early have had to keep pace with a constantly changing environment. Building web scraping infrastructure can be difficult but staying up to date on the latest web scraping trends and technologies can be an even greater challenge given the constantly changing nature of the internet at large.
Among the general population, web scraping is still relatively unknown, but awareness is growing.
4) Information for business professionals
How can web scraping help my business?
Do you currently collect data manually? Is there information online that would be helpful to have? If the answer to either of those questions is "Yes," then your business may be a good candidate to implement a web scraping strategy. Web scraping can help your business make better-informed decisions, reach targeted leads, or track your competitors. Consultation with an experienced web scraper can help you discover what is possible.
What are my options?
You have many options in deciding how to implement a web scraping strategy. Below we outline the five primary ways companies employ web scraping today.
Option 1) Manual web scraping
Manual web scraping the process of manually copying and pasting data from websites into spreadsheets. Commonly, manual web scraping naturally arises out of a business need. It may begin in the form of occasional copying and pasting of data by business analysts but eventually may become a formalized business process. Companies who choose this option have identified a need for web scraped data but generally do not have the technical expertise or infrastructure to automatically collect it.
- Pros
- No new skills to learn
- The fastest solution for small, one-time tasks
- Cons
- Not feasible for large scrapes
- Very inefficient for recurring scrapes
The following exhibit illustrates the next four web scraping strategy options:
Exhibit: Options for automated web scraping
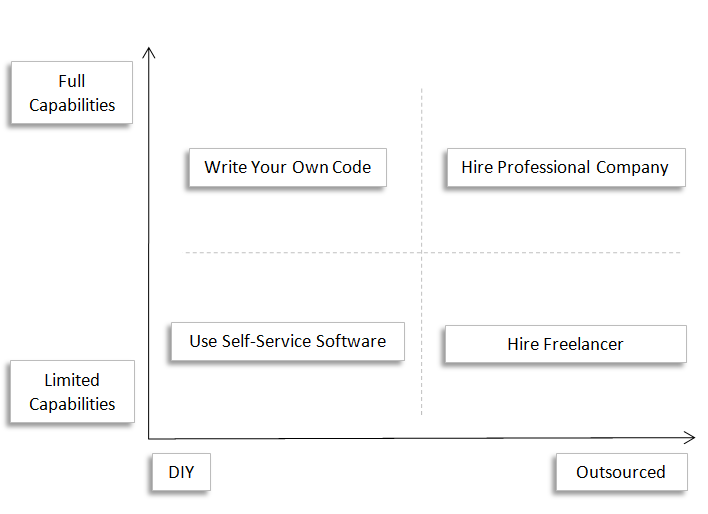
Option 2) Write your own code
The second option is to write your own custom code using a programming language such as Python. Companies who already employ computer programmers may find this to be a natural progression although a learning curve still exists.
- Pros
- Much more efficient than manual web scraping for large or recurring projects
- Can be fully customized to your needs
- Cons
- Steep learning curve or high expense to hire staff with necessary skills
- Distraction from core competency and need to maintain web scraping infrastructure
Option 3) Use self-service, point-and-click software
The third option is to use a self-service point-and-click software, such as Mozenda. Many companies maintain software that allows non-technical business users to scrape websites by building projects using a graphical user interface (GUI). Instead of writing custom code, users simply load a web page into a browser and click to identify data that should be extracted into a spreadsheet.
- Pros
- Easier to learn than writing own code
- Allows non-programmers to set up automatic scrapes
- Cons
- Costs can add up quickly if based on usage
- Less complexity also means less flexibility to customize projects for all use cases; point-and-click software is generally only well-suited for the most basic scrapes
Option 4) Hire a freelancer
The fourth option is to hire a freelance programmer to extract the data that you need.
- Pros
- You don’t need any technical knowledge
- You don't need to manage code or infrastructure
- Cons
- Freelancers greatly vary in the quality of their work, and it can be difficult and time-consuming to select a competent one
- Communication can be slow and/or difficult (especially if offshore)
- Significant management and oversight of the project is required
Option 5) Hire a professional company
The fifth option is to hire a professional web scraping company to manage your web scraping projects. Discount firms exist and can offer cheap prices for simple, well-defined projects but their quality may vary. At the other end of the spectrum, full-service firms will act as dedicated consultants to understand your business needs, develop a customized solution, and deliver the data that you need.
- Pros
- Easiest and most efficient solution
- Requires the least work and back-and-forth communication from you
- Cons
- Need to vet the quality of the company
Factors to Consider
When deciding which option to pick, you should keep the following factors in mind:
- Willingness to learn technical skills or hire new staff: Do you want to spend time learning technical skills yourself? Will the labor expense of dedicated in-house staff outweigh the benefits?
- Importance of data: How critical is this data? What would happen if you stopped receiving this data? What would happen if you received erroneous data?
- Customization level that is needed: How simple or complex is your task? May this change in the future?
- Total cost in both dollars and time: How valuable is your time? When factoring in your own time, which option is the cheapest?
5) Top web scraping tools and services
What is the best web scraping tool?
Unfortunately, there is no single best answer to this question as the answer will depend upon your unique circumstances. In general, we recommend the Scrapy framework for Python for technical users. For non-technical users, we generally recommend hiring a full-service firm. However, below we provide more information on all of your options so that you can make the best decision for your needs.
Full-service professional web scraping companies
Open-source programming languages and tools
Point-and-click web scraping software
Related software
Web Scraping vs. Robotic Process Automation
Both web scraping and robotic process automation refer to the automation of tasks that could be done manually. However, web scraping is primarily concerned with extracting data from websites while robotic process automation is primarily concerned with the completion of traditional business tasks, such as invoice data entry, within other software programs. UiPath and Kofax are two such examples of leading RPA software platforms.
Can I use Alteryx for web scraping?
Alteryx is software that is used for managing data pipelines. It allows users to load data from raw data sources, apply transformations, and output the data to be read by other applications. Alteryx may be part of web scraping infrastructure but does not perform the actual extraction of data from web sites.
6) Developer best practices
Etiquette for scraping websites
Web scrapers should follow generally-accepted best practices so that they 1) do not violate any laws and/or 2) place an undue burden on the sites they are scraping.
The two broadest and most important principles to keep in mind are
- Do not overload the site that you are scraping (no "DDOS" attacks)
- Do not hack into machines (do not use unauthorized credentials or employ malware)
Various organizations suggest many other rules to follow. These are generally stricter than what most professional web scraping organizations adhere to but do provide helpful guidelines. Two notable examples are listed below.
Do I need to follow robots.txt?
Robots.txt is a file hosted on a website that contains instructions on how bots should interact with the site. For example, it may prohibit certain bots from accessing certain parts of the website. This is not enforceable, however, by the website. Bots must voluntarily follow these rules for the instructions to have an effect. Web scrapers generally do not follow robots.txt instructions, and US courts have been sympathetic to that view. Still, depending on your specific use case, following robots.txt may be prudent.
A bot that chooses to follow robots.txt instructions will look for its name (specifically its "User-Agent")
in the set of instructions and then see what is allowed and disallowed. An asterisk (*) denotes that all bots
should follow a set of instructions. In the example below, all bots are allowed to scrape
https://example.com/categories but are disallowed from scraping
https://example.com/products, except bots with "BadBot" as the User-Agent, which are disallowed
from scraping anything (a slash means nothing hosted on the site can be accessed).
Example robots.txt file:
User-agent: *
Disallow: /products
Allow: /categories
User-agent: BadBot
Disallow: /
You can find a website's robots.txt file by going to https://[domain name].com/robots.txt. For
example, you can find Amazon's robots.txt file by going to https://amazon.com/robots.txt.
For more information on robots.txt, see Google's guide here.
Common tools and techniques
Request types
In general, web scrapers can load content in one of two ways. First, they can simply issue an HTTP request to a web server and retrieve its response. Or, second, they can load a web page in a real web browser. Tools such as Selenium (https://www.selenium.dev/) and Playwright (https://playwright.dev/) can be used to automate user actions in a full browser. Direct HTTP requests are generally preferable when possible, but each method has pros and cons, which are listed below.
Direct HTTP Requests
- Pros
- Faster
- More reliable
- Less resource-intensive
- Can collect data that is loaded in the background but not shown on a web page
- Cons
- Cannot be used for all web pages
- May be more complex than simply loading a page in a browser
Python Example:
import requests
response = requests.get('https://api.github.com')
Full Browser Requests
- Pros
- Exactly emulates what a typical user would see and do
- Can be used to collect data from any web site
- Cons
- Slower and more resource-intensive
- May require more maintenance if the structure of web pages frequently changes
Python Example:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://github.com')
Handling AJAX requests
AJAX requests are requests that a browser makes in the background after an initial page has begun loading.
Commonly, the data that web scrapers wish to extract is loaded through an AJAX request, and, oftentimes, this
data can be accessed by hitting an API endpoint that returns structured data. For example, Peloton's class
schedule can be found at this URL: https://members.onepeloton.com/schedule/cycling. However, the
actual class data is loaded through an AJAX request. If you were to issue a direct HTTP request to
https://members.onepeloton.com/schedule/cycling, then you would not receive the class schedule
data. You could use a full browser to load the page, but you could also emulate the AJAX request by issuing a
direct HTTP request to the underlying API that is being called.
Chrome DevTools can be used to see all network requests that are being made when a page is loading. In the first screenshot, you can see that the api.onepeloton.com endpoint is being called when the page is loaded. You can see the data that it returns in the second screenshot. Directly hitting this underlying API has several advantages: 1) it reduces the load on the site because fewer requests need to be made, 2) responses are usually well-structured and easier to parse, and 3) less maintenance is usually required because API responses less frequently change. Thus, it is preferable to use an underlying API when available.
Peloton Exhibit 1:
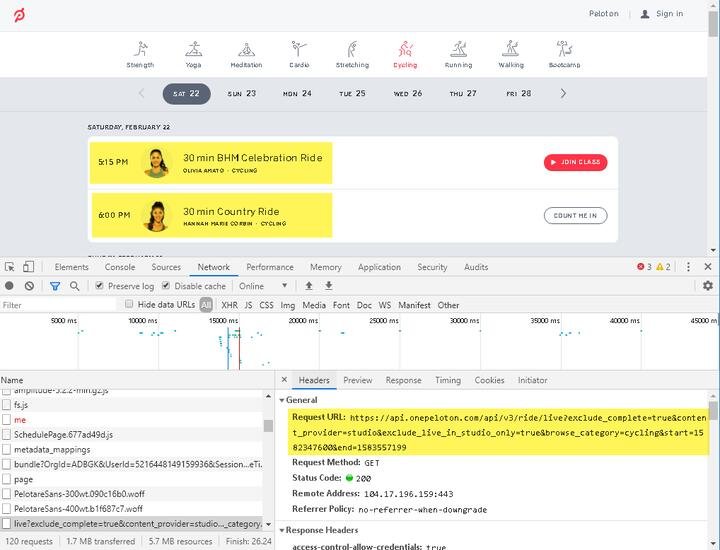
Peloton Exhibit 2:

What is a headless browser?
Some web scraping projects are better suited toward using a full browser to render pages. This may mean launching a full web browser in the same way a regular user might launch one; web pages that are loaded on visible on a screen. However, visually displaying web pages is generally unnecessary when web scraping leads to higher computational overhead. Furthermore, projects commonly are run on servers without displays. Headless browsers are a way to solve this problem. Headless browsers are full browsers without a graphical user interface. They require less computing resources and can run on machines without displays. A tradeoff is that they do not behave exactly like full, graphical browsers. For example, a full, graphical Chrome browser can load extensions while a headless Chrome browser cannot (source).
Cloud computing
Individual developers may choose to run web scraping projects locally on their own computers, but cloud computing services provide many advantages for larger projects. The three largest cloud computing providers are Amazon Web Services, Microsoft Azure, and Google Cloud Platform, but numerous others exist. The most commonly used resources are the following:
- Virtual machines: These are the computing resources that execute web scraping code. Linux is generally a good choice, but Windows operating systems can also be used.
- Object storage: This provides cloud-hosted storage for web scraped data and is usually accessed through convenient APIs, such as the boto3 package for Python.
- Relational databases: These provide convenient ways to store and access web scraping data. MySQL and PostgreSQL are usually good options for most projects.
Proxy providers
Web scrapers commonly use proxies to more closely emulate the traffic of normal users. This ensures that they maintain the same level of access to data that a normal user would enjoy. Proxies also allow web scrapers to access information that may be different or restricted based on certain geographies. Many commercial proxy providers exist. They generally offer access to proxies on a monthly subscription basis.
Commercial proxy companies provide many different types of proxies that are optimized for different use cases. Some common types of proxies offered include the following:
- Static proxies: Static proxies come in the form of an IP address and port number (eg. "2.2.2.2:1234"). All requests are routed through the proxy server. Static proxies can be either dedicated, which means that the proxy is assigned to a single customer, or shared, which means that the proxy is shared among multiple customers. Dedicated proxies are more expensive but may be more cost-effective than using shared proxies if the difference in performance is great enough. Dedicated static proxies are generally the fastest proxies that can be used but are easier for websites to detect.
- Rotating proxies: Rotating proxies typically come in the same form of a static proxy. Providers give users an IP address and port number to connect to. However, the proxy operates very differently from a static proxy. Instead of routing all requests through the same IP address, a rotating proxy routes each request through a different IP address. This best simulates independent page views from multiple users.
- API proxies: API proxies offer similar benefits to static and rotating proxies but can be more flexible in how they are used. Static and rotating proxies must be used in conjunction with software that allows proxy servers to be set. In contrast, API proxies can be used in place of any HTTPS request. Instead of accessing a proxy through an IP address and port number, the API is accessed through an HTTPS request, such as "https://api.proxycompany.com/?token=abc&url=http://example.com" (where "http://example.com" is replaced with the relevant url).
Proxies FAQ
-
How can I setup my own proxy server? Instead of buying access to proxies through an outside vendor, a web scraping could host their own proxies. This tutorial provides instructions on how to set up a basic proxy on a cloud-hosted Linux server: Tutorial.
-
How do I set up a proxy in Firefox? Firefox provides an easy way to directly set a proxy within the browser settings. Instructions can be found here.
External resources
Stack Overflow web scraping questions
GitHub repositories
Recommended book to learn Python
7) Legal considerations
Disclaimer: The information found on this website is for informational purposes only and does not constitute legal advice. Please consult a lawyer if you need legal advice.
Is web scraping legal?
This may not be the first question you ask, but it commonly comes up from time to time. Web scraping, in general, is legal, but lines can be blurred between what and what isn't permissible. As in many areas of tech, web scraping has advanced faster than the legal system could keep up. As a result, some aspects of web scraping fall into legal grey areas. This, of course, depends on the jurisdiction in which you operate. Laws tend to be more restrictive across Europe and less restrictive in countries such as China, India, and Russia. US laws fall roughly in between. Although ambiguity may exist, there's much you can do to make sure you never come close to that line.
What are the relevant laws in the United States?
Several laws in the US relate to some aspects of web scraping. The following lists the most common concerns:
- Breach of contract (Civil): Breach of contract is a civil wrong that occurs when one party of an agreement breaks his or her obligations under that agreement. US courts have generally found that this does not apply to most websites, which do not require affirmative acceptance of terms of use.
- Copyright infringement (Criminal): Copyright infringement occurs when a copyrighted work is redistributed, published, or sold without proper authorization. Copyrighted material is usually not the subject of web scraping projects, but care must be taken not to violate copyright law.
- Trespassing (Criminal): The Computer Fraud and Abuse Act (CFAA) prohibits computer trespassing, accessing a computer without authorization. This basically prohibits "hacking" and generally does not apply to information that is publicly available online.
News
- May 19, 2022: The US Department of Justice revised its policy to direct that good-faith security research should not be charged under the CFAA. (link)
- May 11, 2022: LinkedIn settled its lawsuit against Mantheos, who agreed to cease scraping LinkedIn and destroy all previously scraped data. (link)
- April 18, 2022: The US Ninth Circuit Court of Appears reaffirmed its original decision and ruled that scraping publicly accessible information does not violate the CFAA. (link)
- June 3, 2021: The Supreme Court narrowed the scope of the CFAA. (link)
- March 27, 2020: A US Federal court ruled that violating a web site's terms of use does not violate the CFAA. (link)
- September 9, 2019: The US Ninth Circuit Court of Appeals reaffirmed the District Court's preliminary injunction forbidding LinkedIn from denying hiQ access to publicly available LinkedIn profile pages. (link)
What are the precedent court cases in the United States?
Several lawsuits have been filed in the US against companies because of their web scraping acctivity. The following is a list of the most prominent court cases:
- Van Buren vs. United States (link)
- Hi2 vs. LinkedIn (link)
- Craigslist vs. RadPad (link)
- Sandvig vs. Sessions (link)
- Ticketmaster vs. Prestige (link)
- BidPrime vs. SmartProcure (link)
- Alan Ross Machinery Corp vs. Machinio Corporation (link)
What law firms specialize in web scraping?
Several law firms have developed specific web scraping expertise. They regularly publish articles on legal topics related to web scraping and provide customized advice to their clients. The following is a sample of relevant firms:
- Schulte Roth & Zabel https://www.srz.com/
- Proskauer https://www.proskauer.com/
- Ward PLLC https://wardpllc.com/
- ZwillGen https://www.zwillgen.com/
8) Detection and prevention
While web scraping can be used for many good purposes, bad actors can also develop malicious bots that cause harm to website owners and others. Professional web scrapers must always make sure that they stay within the bounds of what is found to be generally acceptable by the broader online community. Web scrapers must be sure not to overload websites ways that could disrupt the normal operation of that site.
Can websites detect web scraping activity?
Websites do have ways of detecting web scraping activity. Some websites are particularly susceptible to illegal web scraping and may wish to limit their risk by putting barriers in place to block automated traffic. These websites seek to identify traffic that originates from an automated bot and then prevents that bot from accessing the site. Websites can identify automated traffic through one or a combination of the following means:
- Websites may require Javascript, which can return information about the computer and browser making the web page request
- Websites can log IP addresses
- "Headless" browsers, commonly used by bots, can be detected
- User behavior can be tracked
- Captchas can be implemented
- Sites may require delays, which slow bots, before granting access
- Websites may implement 3rd party services which may use even more sophisticated techniques (examples include Akamai, CloudFlare, and Distil Networks)
Once automated traffic is identified, websites can then choose how to handle that traffic. The website could respond with the following actions:
- Limiting the rate of page requests
- Denying access to parts of the site
- Returning data designed to interfere with the bot's actions (eg. returning an infinite loop of dummy URLs)
- Temporarily banning bots from the website based on browser fingerprint attributes
- Temporarily banning traffic based on an IP address (This could have unintended consequences because users may share public IP addresses. E-commerce companies could lose sales if they prevent legitimate customers from accessing the site.)
- Permanent IP ban (This is the most extreme and not a common response because of the significant collateral damage that it would cause.)
Experienced web scrapers may have ways to work around these measures, but they certainly do increase the difficulty in scraping the site.
9) Tutorials
What programming languages are used for web scraping?
Many programming languages can be used to build web scraping projects — such as Python, Ruby, Go, R, Java, and Javascript — but we recommend using Python since its the most popular one for web scraping. Because of this, many libraries and frameworks exist to aid in the development of projects, and there's a large community of developers who currently build Python bots. This makes recruitment of developers easier and also means that help is easier to get when needed from sites such as Stack Overflow.
Conveniently, Python also has strong support for data manipulation once the web data has been extracted. R is another good choice for small to medium scale post-scraping data processing.
Our favorite tutorials
These are our favorite tutorials to learn web scraping and related skills:
- Scrapy: Scrapy
- Selenium: Guru 99
- SQL: SQL Tutorial
- XPath: W3Schools
- Regular expressions ("Regex"): RegexOne
- Javascript: W3Schools
- BeautifulSoup: The Programming Historian
- data.table for R: CRAN
Our favorite Python libraries
These are our favorite Python libraries to use when building web scraping projects.
-
Scrapy:
pip install scrapy -
Selenium:
pip install selenium -
Dataset:
pip install dataset -
Pandas:
pip install pandas -
Dateparser:
pip install dateparser -
Browsermob:
pip install browsermob-proxy -
BeautifulSoup:
pip install beautifulsoup4 -
HTML to Text:
pip install html-text -
Pillow:
pip install pillow -
Paramiko:
pip install paramiko -
Black:
pip install black -
Yagmail:
pip install yagmail -
pdoc:
pip install pdoc3
10) Public Datasets
These datasets are publicly available and may contain helpful information.
[Geography] GeoNames
A vast amount of geographical data can be downloaded from geonames.org. For example, they maintain files that contain all US zip codes (and all postcodes worldwide, for that matter).
[Demographics] United States Census Bureau
The US Census Bureau publishes a wide array of demographic data, including population statistics.
[Finance] Nasdaq Stock Screener
A CSV file containing a list of all publicly traded stocks in the US can be downloaded here.
[Economy] Federal Reserve
The St. Louis branch of the US Federal Reserve publishes time series tracking aspects, such as GDP and inflation, of the US economy.
[Economy] US International Trade Comission
The USITC publishes data on imports and exports by category.
[Economy] Zillow
Zillow leverages their proprietary data to publish a variety of time series tracking the US housing market.
[Economy/Politics] NYC Open Data
NYC maintanis a portal where you can download datasets covering various aspects of the city, including business, governemtn, education, environment, and health.
[Various] FiveThirtyEight
FiveThirtyEight publishes a wide variety of data that backs up articles that they publish at fivethirtyeight.com.
11) Glossary
AJAX Request: a page request that is made in the background after the initial page request
BeautifulSoup: an open-source python library used to parse text, such as HTML web pages, as an alternative to XPath
bot: a web scraping program
cookie: data that is stored in a user's browser and modified by websites; they are commonly used for authentication
CSS selectors: a method used to specify which parts of a web page should be extracted by using CSS attributes
crawler: a program that systematically visits pages across a website or websites
data scraper: a web scraping program
developer: a person who writes code; a programmer
headers: extra information that is sent to a website when a browser requests a page
hidden APIs: web APIs that are used by a website to load data into its web pages; commonly used by web scrapers to more easily access data
hacker: 1) an informal term for a self-taught programmer or 2) someone who gains unauthorized access to a computer
HTML: a structured language in which most web pages are written
Javascript: a programming language used to dynamically load content in web pages
Python: an open-source programming language that is commonly used for web scraping
spider: a web scraping program
Scrapy: a popular open-source library for Python that is used for web scraping
Selenium: a popular open-source library for Python that automates web browser actions
screen scraper: a web scraping program, generally one that scrapes information visible on a website (as opposed to invisible)
proxy: a server through which web traffic is redirected
User-Agent: a name that identifies a browser or bot requesting a web page; this is not unique to a browser or bot and can be manually specified
virtual machine: an emulated computer that can be accessed and used as if it were a standalone physical machine; cloud service providers offer virtual machines for rent
XPath: a language used to specify which parts of a web page should be extracted by using HTML attributes
web harvester: a web scraping program
web scraping: the extraction of data from websites, typically through automated means
web scraped data: data that is collected through web scraping
web scraper: a person who engages in web scraping